Measure And Optimize Time To First Byte (TTFB)
TTFB (Time to First Byte) measures how quickly your website server responds to requests. It can have a significant impact on your overall site speed and user experience.
This article explains the Time to First Byte (TTFB) metric, how to measure it, and how to optimize it.
What is Time to First Byte?
The Full TTFB measures how long after navigation the first byte of the HTML document response is received by the browser. This is what Google reports as part of its CrUX dataset.

However, different tools use different definitions for TTFB.
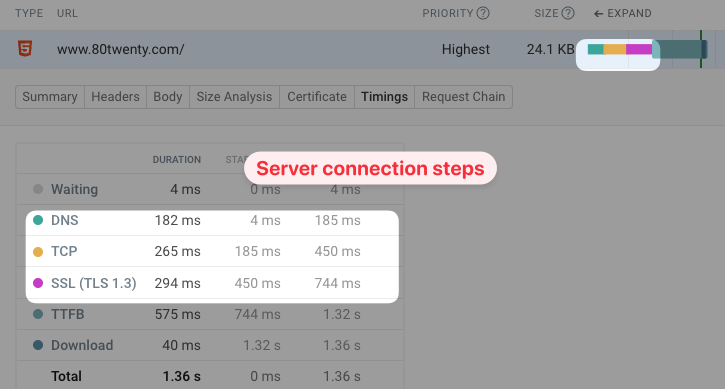
When looking at the individual components of a request, TTFB often only measures the duration of the HTTP request itself. Time spent establishing a server connection is not included. We've marked this as HTTP Request TTFB in the diagram.
Chrome DevTools used to describe this as Waiting (TTFB) but now uses the term Waiting for server response to avoid ambiguity. In Lighthouse this metric is called server response time.
Why is Time to First Byte important for user experience?
The longer the server response time, the longer website visitors have to wait for content to become visible. The Time to First Byte for the HTML document is the essential first step when loading a website.
In this request waterfall you can see a slow document request with a 3.1 second TTFB. That contributes significantly to the overall page load time of 5.7 seconds.
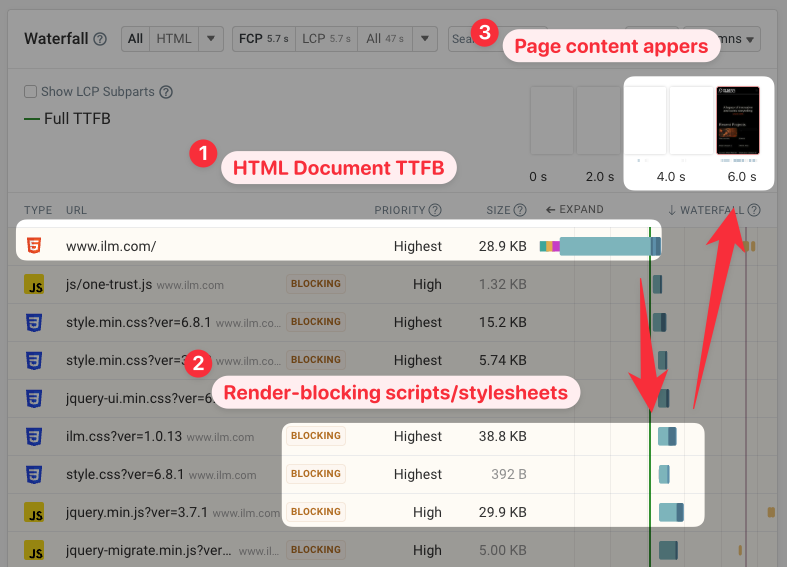
In contrast, a low TTFB makes your website render more quickly.
On this website, we can see that the server responds within 217 milliseconds, and the page is fully loaded in less than half a second.

However, receiving the first byte often isn't sufficient as most pages have additional render-blocking resources that are loaded after the initial document request.
The First Contentful Paint and Largest Contentful Paint metrics measure when content actually becomes visible to the user.
This filmstrip shows a website with a fast TTFB that still takes a long time to load. In this case you need to take additional steps to improve your website performance.

What are the components of TTFB?
The four core components of the Time to First Byte metric are:
- DNS lookup
- TCP connection
- SSL connection
- HTTP request time
Before downloading a resource on the internet, browsers first need to establish a connection to the website server. After that, the actual request for the file can be made using HTTP.
Sometimes there are additional components to TTFB, for example:
- Wait time, waiting for service workers or cache lookups
- Redirect time if the initial URL the user opens redirects to a different URL
When viewing TTFB data you'll also often see the download time listed. But download time is not part of the TTFB, as it covers all bytes of the response instead of just the first byte.
What does the Full TTFB metric consist of?
The full TTFB metric in DebugBear includes any redirects that are part of the HTML document request, time spent establishing a server connection, and time requesting the document.
This matches how Time to First Byte is measured in Google's Chrome User Experience Report (CrUX), which Google uses as a ranking factor.
Does TTFB include redirects?
Redirects are included in the Full TTFB measurement.
In the example below, the initial server response consists of an HTTP redirect rather than HTML in the response body that the browser can display. The actual First Byte time is recorded when the second HTTP request returns an HTML document.
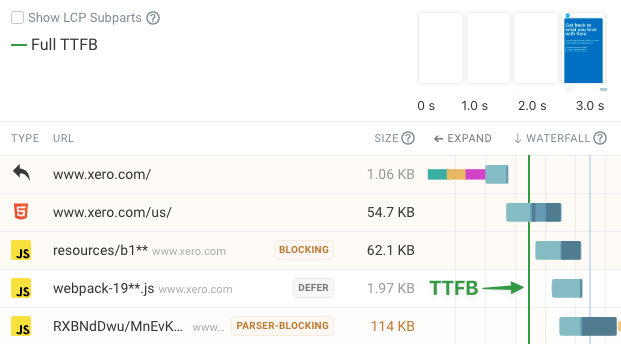
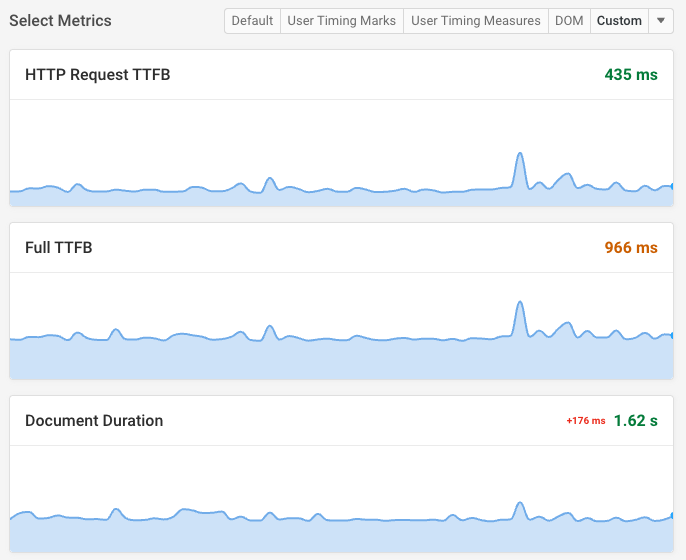
HTTP Request TTFB
Every HTTP request that receives a response has a Time to First Byte. When talking about requests after the initial document request, TTFB usually only refers to the time spent waiting for a response to the HTTP request.
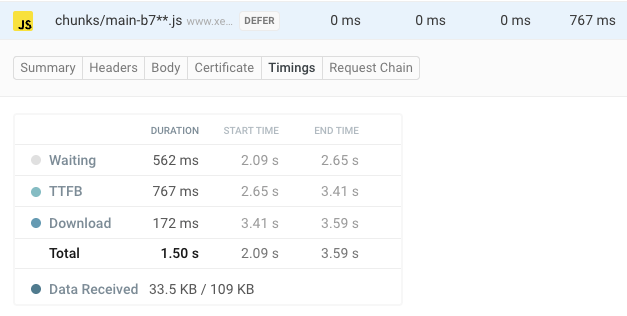
For example, you can see the per-request TTFB in DebugBear's Requests view by clicking on any request and then selecting Timings in the detail view. Here it forms only one part of the overall request duration.
We can also show all TTFB timings as part of the request waterfall – just select 'DNS, TCP, SSL, TTFB' in the Columns dropdown in the top-right.
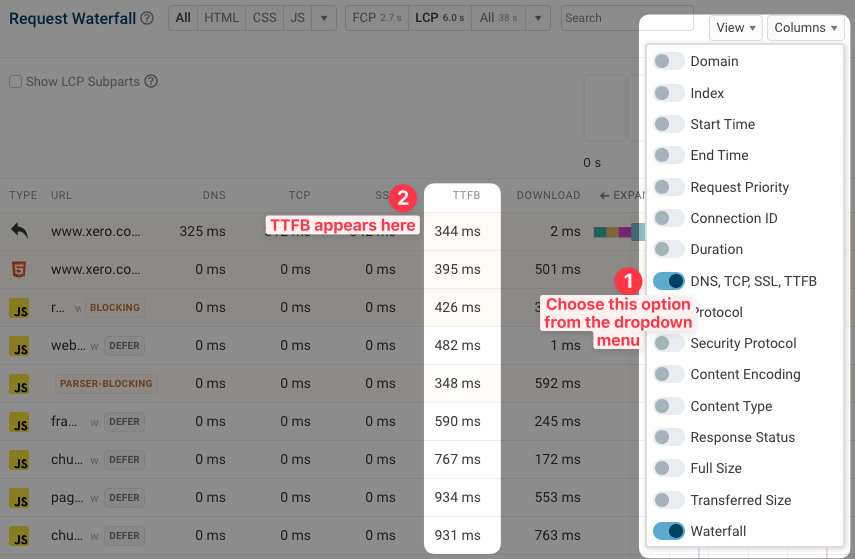
You can also view different document timings:
- HTTP Request TTFB: only looks at the HTTP request itself
- Full TTFB: measures Time to First Byte including connection setup and redirects
- Document duration: measures HTML request duration including download time
Early hints and Time to First Byte
Early Hints are a protocol technology that lets servers tell the browser about additional page resources before the HTML document has started loading.
You can see an example of this here, where two fonts start loading before the first byte of the document arrives.
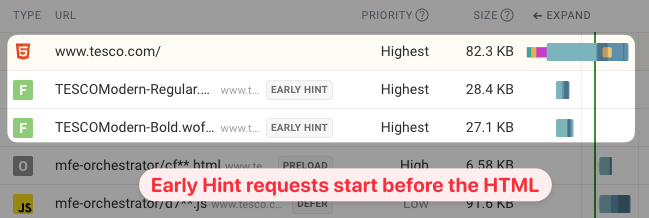
Is the first byte the first document byte or does the early hint response data also count? Currently this is not consistent across tooling.
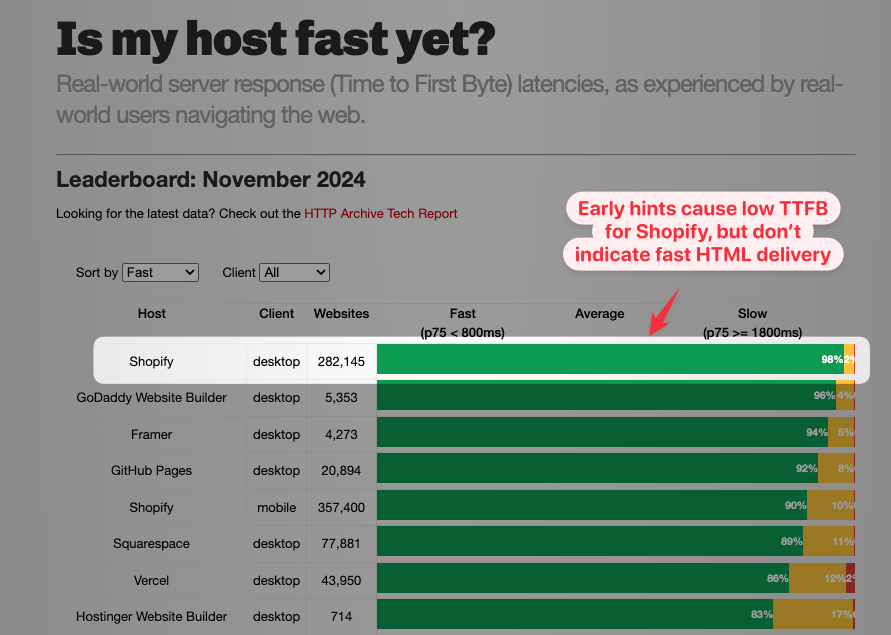
When looking at data, prefer user experience metrics like Largest Contentful Paint. TTFB-based rankings can be confusing, for example the "Is my host fast yet?" website reports great TTFB for Shopify, but this only reports Early Hints and not actual HTML delivery.
Does TTFB impact SEO?
Time to First Byte is not one of the Core Web Vitals metrics and Google does not directly use it as part of its search engine rankings.
However, TTFB does impact the Largest Contentful Paint and a slow server response can still hurt your SEO.
Google does include TTFB as part of the CrUX dataset for debugging purposes. You can use PageSpeed Insights to test what TTFB looks like for real users.

You can use DebugBear Core Web Vitals monitoring to keep track of TTFB and other performance metrics across lab-based tests, Google CrUX metrics, and real user data – and even benchmark your site against others in your industry.
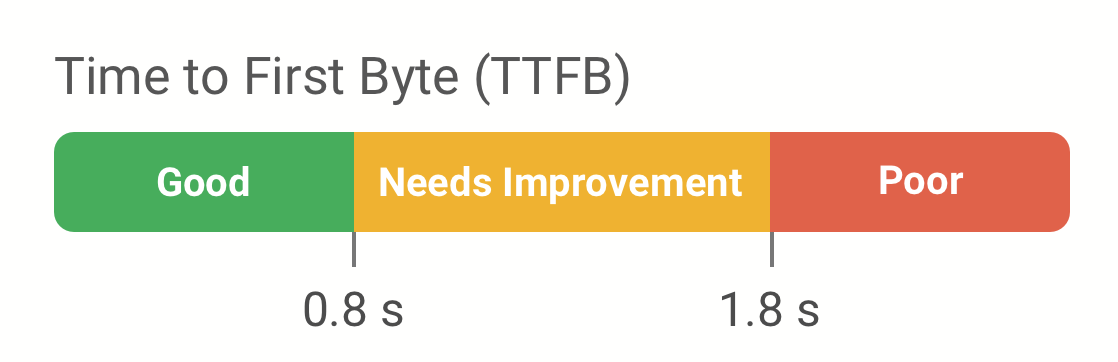
What is a good TTFB?
Google considers a Full TTFB of 800 milliseconds to be good. Values above 1.8 seconds are considered poor.
Which resources are commonly affected by slow TTFB?
Requests that load dynamic content that needs to be generated for each request typically have a higher Time to First Byte. This usually applies to the initial document request or later XHR requests that load additional data.
Static resources like images and JavaScript files can generally be returned quickly by the server.
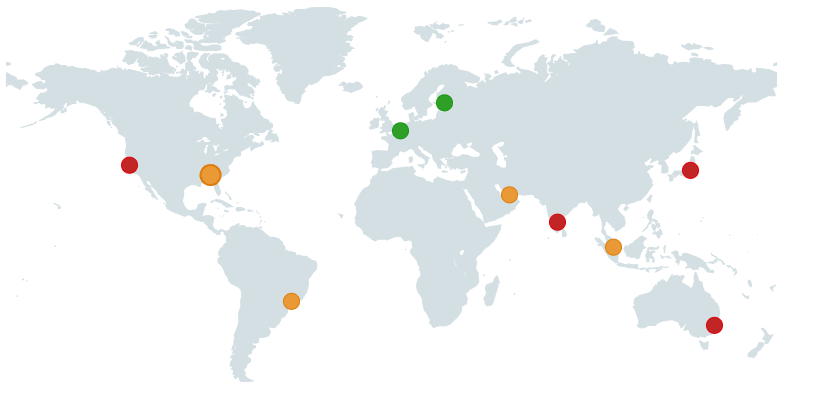
Test TTFB from different test locations across the globe
Using a free TTFB testing tool is a quick way to see how your website performs across the world. You simply provide a test URL and it's then accessed from multiple test locations to see how quickly the HTTP response comes in.
This way you'll know how performance varies globally and whether you need to optimize the experience for certain users.
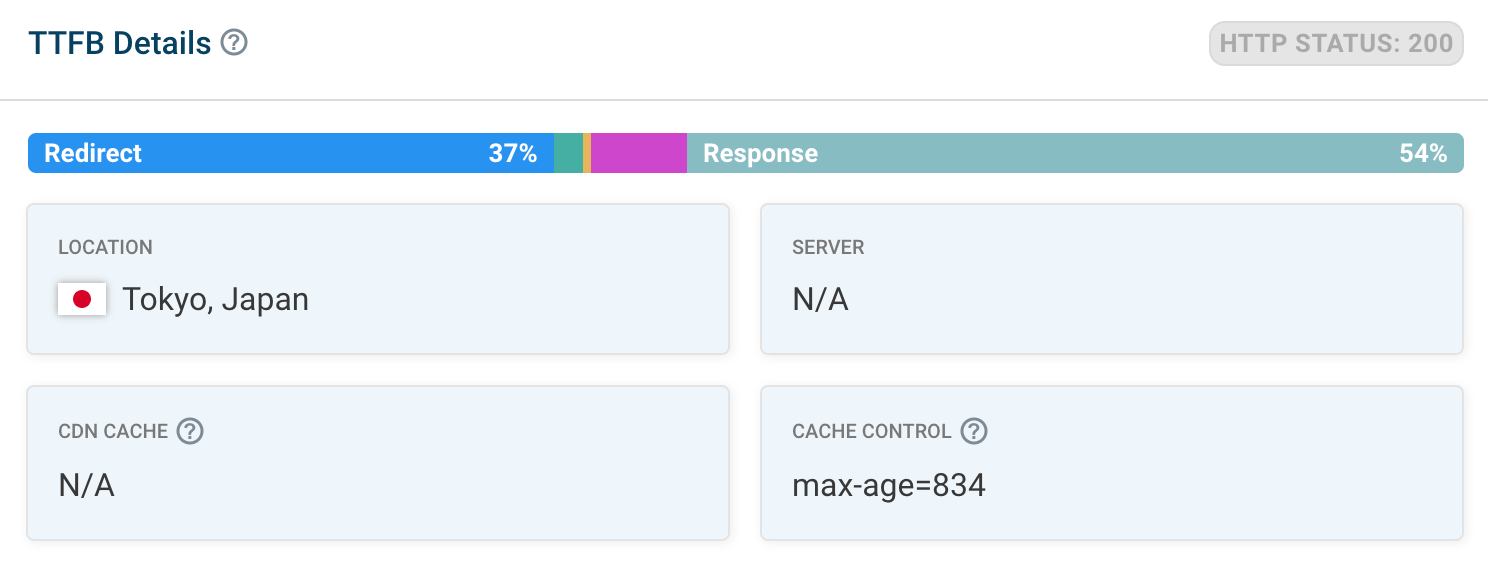
You'll also get a breakdown of the different TTFB components. That way you can see whether poor performance is caused by latency or by server processing.
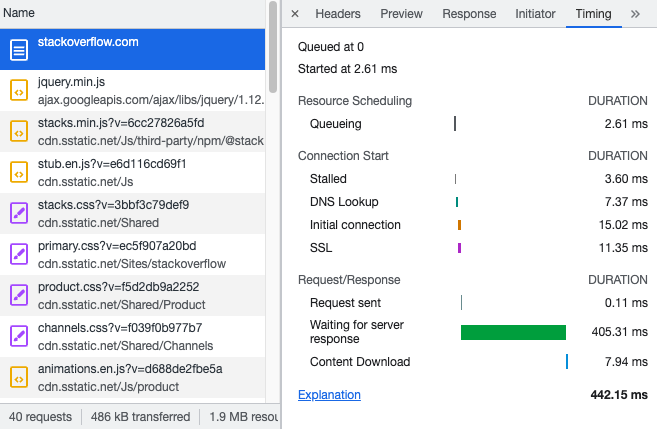
Measuring TTFB in DevTools
As mentioned above, PageSpeed Insights is a great tool to check if a slow TTFB is a problem for real users. Chrome DevTools can help you test TTFB locally to see if your optimizations are working.
You can find the HTTP Request TTFB in the Network tab of Chrome DevTools. Click on the document request, open the Timing tab, and then check the Waiting for server response value.
If you are looking for the Full TTFB, you can look at the sum at the bottom of the Timing tab. This number does not include redirects; if there are any, you'll need to manually check how long those requests took and calculate the total TTFB value.
TTFB in Lighthouse: Reduce initial server response time
Lighthouse reports include the server response time in the Performance section.
The Reduce initial server response time audit evaluates how quickly the HTML document response was provided after starting the HTTP request.
Like in DevTools, this number does not represent the Full TTFB.
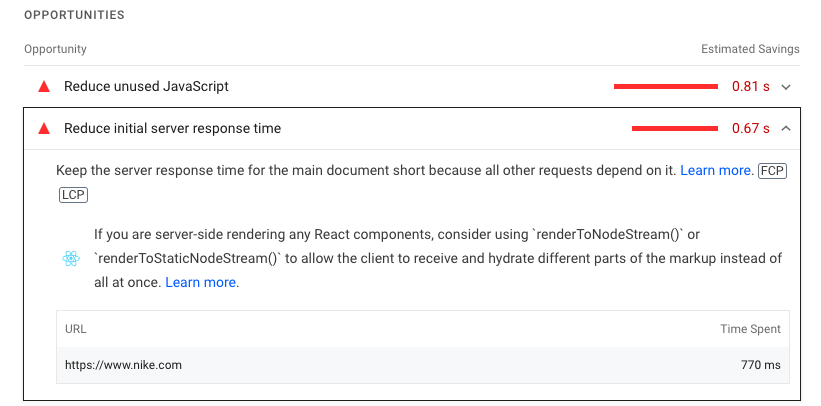
You might need to open the Passed Audits heading to see it.

Measuring real user TTFB with DebugBear
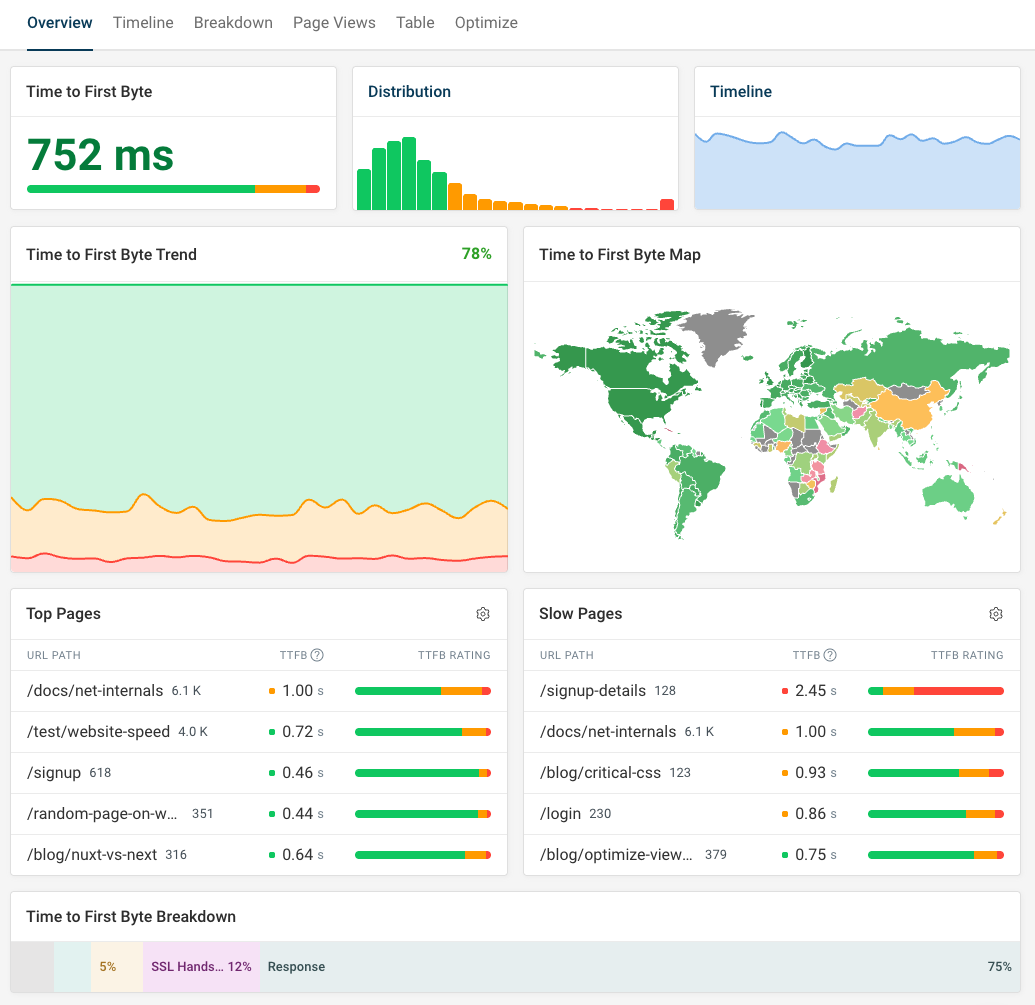
DebugBear real user monitoring (RUM) can measure Time to First Byte for visitors on your website. After setting up RUM you can open the TTFB metric dashboard.
The dashboard shows you:
- Your overall TTFB score (the 75th percentile by default)
- A histogram showing the distribution of visitor experiences
- A trendline showing TTFB over time
- A global breakdown of your TTFB scores
- TTFB on your most popular pages
- Pages with poor TTFB scores
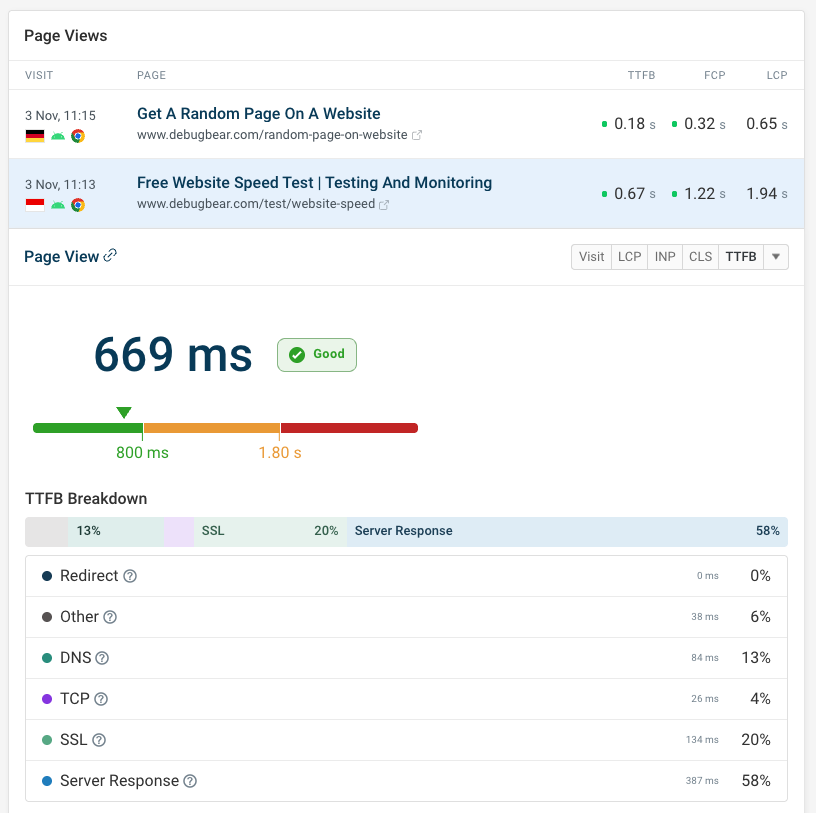
You can also look at specific website visits to see the TTFB component breakdown.
The breakdown tells you how much time different components like redirection or connection time contributed to the overall TTFB score.
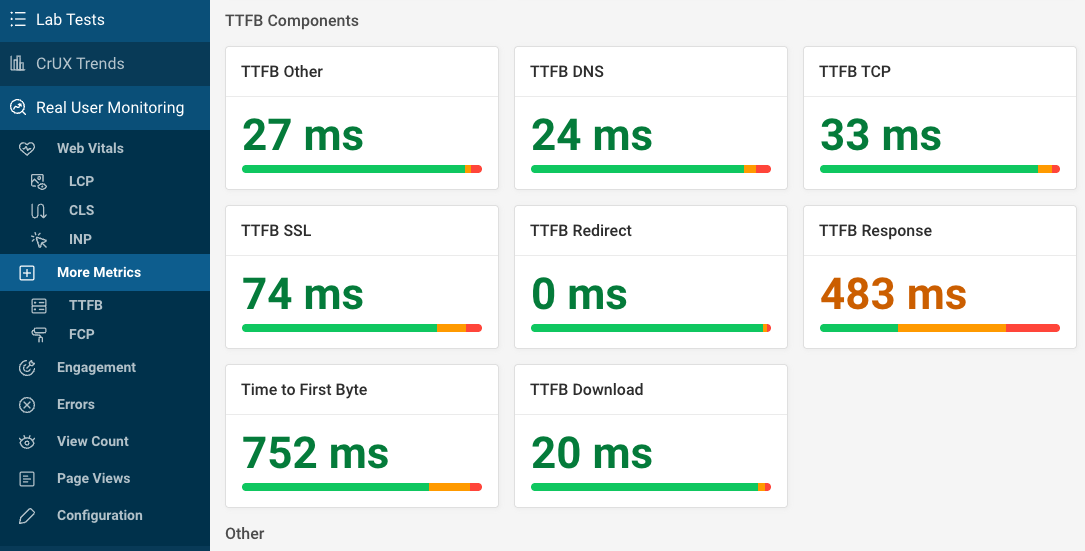
Alternatively, use the More tab to view TTFB breakdown metrics across all visits on your website. Click on each component to view a dedicated monitoring dashboard for that metric.
Here you can also see how long it took for the browser to download the HTML document.
How can redirect time be measured in real user data?
For privacy reasons, browser APIs often restrict what performance information is reported. This applies especially when making cross-origin requests.
When a RUM tool reports a redirect time, this means a same-origin redirect occurred. For example, a website might redirect from example.com/hello to example.com/home.
If a cross-origin redirect occurs, then browsers don't report this as redirect time. For example, if bit.ly/abc123 redirects to example.com/home, then this redirect will be reported as Wait time instead.
What does wait time refer to in real user data?
Wait time can occur for a few different reasons, for example:
- Cross-origin redirects
- Cache lookups
- Service worker request processing
How to improve Time to First Byte
A slow server response time can have a wide range of causes, for example:
- CPU-intensive work on the web or database server
- Slow network round trips and server connections
- Third-party API calls
- Cold launches of "serverless" instances
Let's take a look at how you can resolve these issues.
Reduce CPU-intensive server processing
The more work your server has to do to generate the HTML document, the longer it will take your visitors to get a response. If your page contains a lot of content that is complex to generate, then your website will have a higher TTFB score.
When working with a CMS like WordPress, CPU processing also increases when many plugins are used. Each plugin requires some additional computations, causing a slow overall server response.
Profile server code
A profiler measures where in the code your app is spending most of its time. We'll look at profiling JavaScript code with Node here, but most popular languages have a similar profiler you can use.
When launching your Node server, enable the debugger by passing in the --inspect flag.
node --inspect server.js
// Will print something like this:
// Debugger listening on ws://127.0.0.1:9229/62953438-d65e-4cf6-866a-63a26f8aa57f
Now, go to the browser and open Chrome DevTools on any page.
You'll find a green icon in the top left corner, saying Open dedicated DevTools for Node.js. Click on it to open the inspector window for the Node process.
In the inspector window, switch to the Profiler tab. Click Start and make a request to your local server, so that there's some activity in the profiler recording.

Stop the recording and switch the dropdown from Heavy (Bottom-up) to Chart. You'll see a flame chart showing what the server was up to at any given moment.
Each bar shows a function call in your code. When one function calls another function, that function is placed below the calling function in the flame chart.

In this case the server spent a lot of time getting the list of JavaScript bundles and rendering a Handlebars template. You can then use this information to see which of these steps you can speed up.
Add print statements when profiling isn't an option
Sometimes it's difficult to profile your code, for example when you're running production code in a Platform as a Service (PaaS) environment. You can try just logging how much time was spent to narrow down what's causing a performance issue.
console.time("Request");
// ...
console.time("After authentication");
// Request: 156.22ms After authentication
// ...
console.time("Template rendered");
// Request: 319.23ms Template rendered
// ...
console.timeEnd("Request");
// Request: 588.71ms
Optimize slow database queries
If server responses are slow but the profile doesn't show a lot of processing, your code might be waiting for responses from the database.
To check if this is the case, try logging every SQL query and measure how long it takes. For example, if you're using Sequelize, you can use this code to log the duration of each query.
const db = new Sequelize("database", "username", "password", {
benchmark: true,
logging: function (sql, timeInMs) {
console.log(sql, timeInMs + "ms");
},
});
If the server is making a lot of small queries, consider if they can be merged into one. For example, you might use joins to fetch related data or use WHERE id in (12, 23) to fetch multiple records.
Some queries might be duplicated or altogether unnecessary.
If specific queries take a long time to run, try prepending the SQL command with EXPLAIN ANALYZE to see how the database server is spending its time.
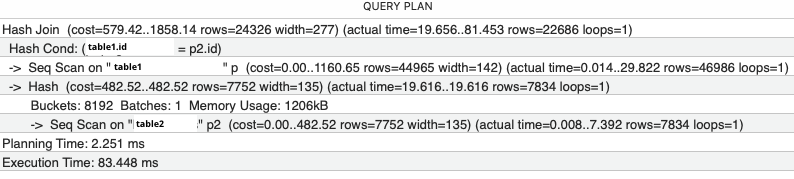
Often, slow queries can be sped up by adding an index to a column that's used for sorting or filtering. This will slow down inserts into the table, but speed up lookups later on.
Speed up server connection time
Establishing an HTTP connection requires multiple network round trips. If your web servers are located far from where your users are each round trip will take longer. A Content Delivery Network (CDN) with many global locations can help with this.
Upgrading to TLS 1.3 can avoid unnecessary round trips. Avoiding Extended Validation certificates prevents expensive certificate revocation requests (OCSP) as part of the connection process.
Avoid accessing third-party APIs
Using external APIs can slow down server response time significantly. Making these API calls means nesting HTTP requests, so your TTFB now also includes the TTFB of the third-party request.
Consider caching responses from these third parties for later use or requesting third-party data through a separate fetch request instead of including it in the initial document HTML.
Choosing API providers with locations close to your own server can reduce the impact of third-party API calls and lower TTFB.
Optimize instance warm-up
If you're using cloud scaling solutions some of your requests may end up being handled by VM instances that are still being provisioned. These cold starts can mean response times of 10 seconds or more.
To avoid this, check your scaling configuration or ensure significant warm server capacity always exists.
Speed up TTFB by lazy loading secondary content
Is all content on the page necessary for the user to benefit from seeing the page? Or can you show the most important content first and then lazy-load additional information?
For example, let's say that rendering a sidebar is slow. You could initially render the page without the sidebar and then load the sidebar via Ajax later on.
Use more and faster servers
This option will cost more, but upgrading to a faster machine can be an easy way to work around performance problems. If multiple requests are competing for resources you can also increase the number of servers used to serve your website.
Reduce TTFB with caching
Caching means saving a value so that you can use it again later, without having to redo the processing that was necessary to get the value originally.
For example, you can cache a response you received from a database, or the HTML for a fully-rendered page template. The cached data can be stored in memory or in a separate cache server.
A simple in-memory cache can look something like this:
let cache = [];
async function getData(dataId) {
if (!cache[dataId]) {
cache[dataId] = getDataWithoutCache(dataId);
}
return cache[dataId];
}
async function getDataWithoutCache() {
/* slow logic */
}
Note that we are caching the promise rather than the result of the getDataWithoutCache call. That way, we don't end up calling getDataWithoutCache again if another getData call is made before the result is available.
While an in-memory cache allows very fast access, it will also increase the memory consumption of your server. To mitigate this, you can use a cache that discards infrequently used items.
Caching HTML on CDN edge nodes
If you can serve the same HTML code to different visitors, then you can achieve minimal TTFB scores by using a CDN cache.
When your server responds with the HTML, the CDN caches the response in addition to sending it to the user. The next time a visitor requests the same resource from the same CDN edge node (i.e., they are in the same geographic region), the CDN can respond without having to contact your website server. This way, very low response times below 200 milliseconds can often be achieved.
Set up caching on WordPress websites
If you have a WordPress website, you can use a cache plugin like WP Rocket to reduce server response time. This way static page content doesn't need to be regenerated.
Make your WordPress site lightning fast with our step-by-step guide to WordPress speed optimization.
Google CrUX data for TTFB debugging
Data from Google's Chrome User Experience Report can help you see how your TTFB scores have been trending and identify potential improvements.
If your page has enough traffic Google provides a 40-week metric history. Run a free website speed test on your website to see this data.
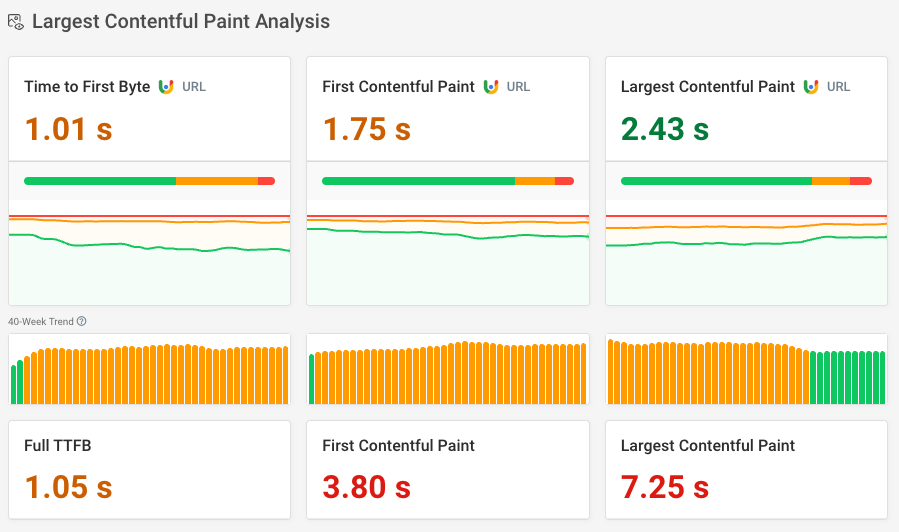
Google also provides additional insights into how visitor behavior and characteristics are impacting the TTFB metric.
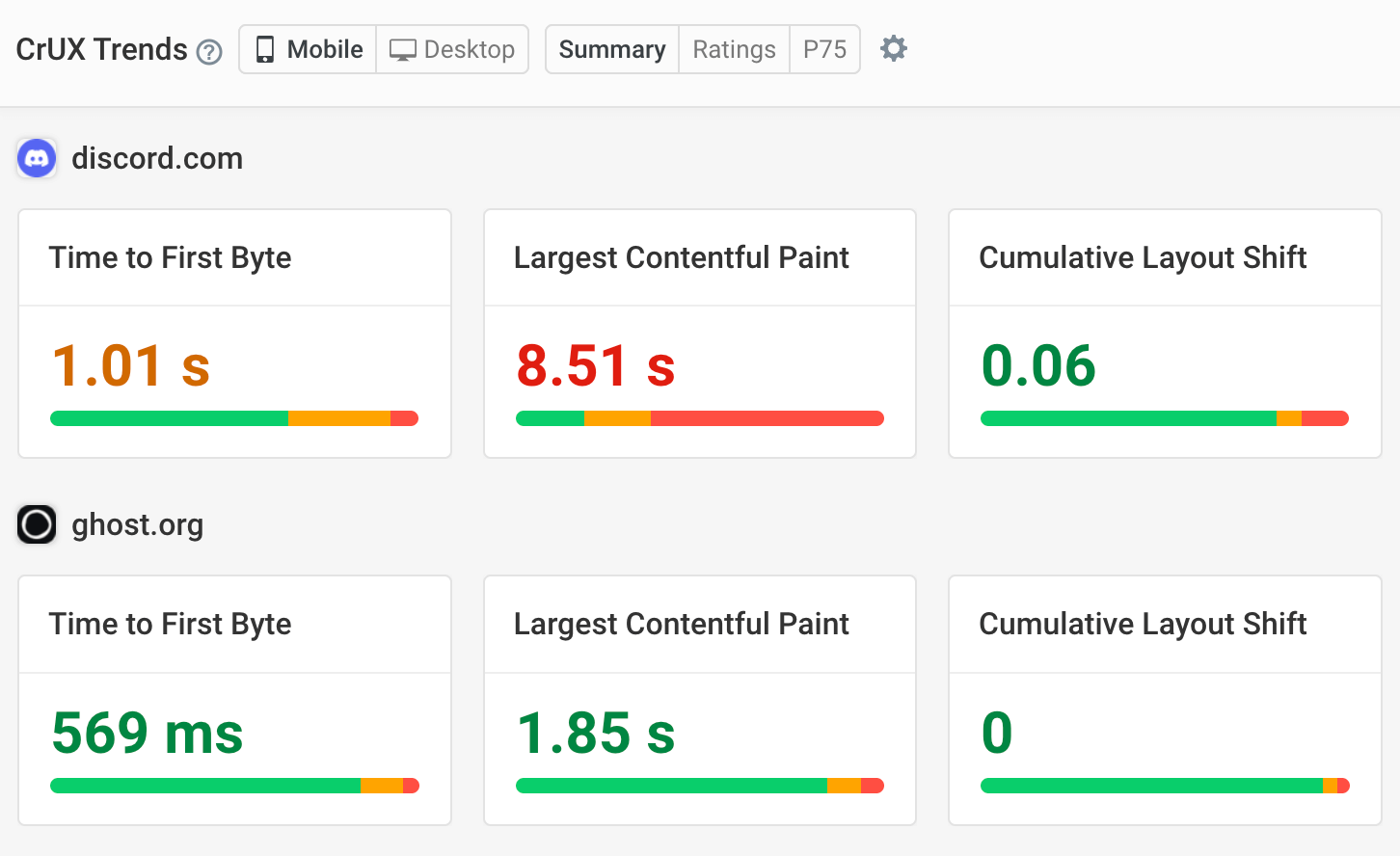
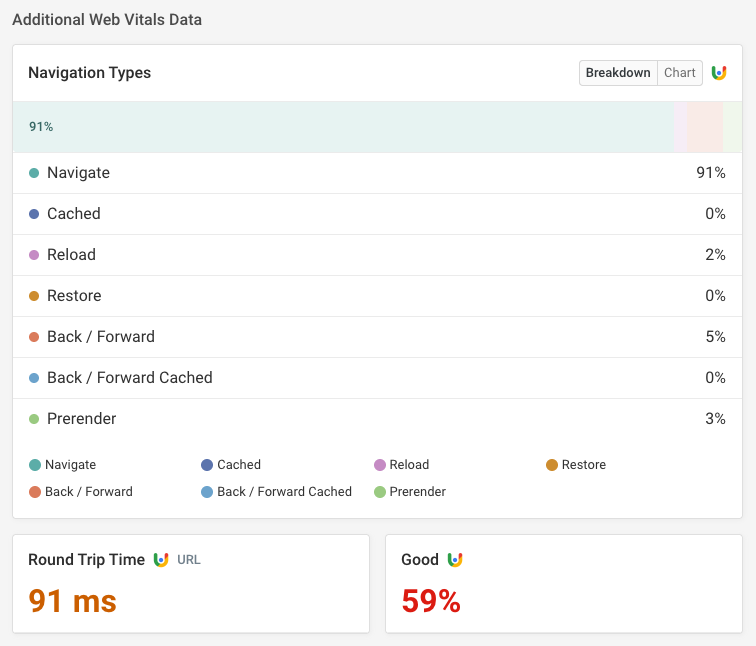
For example, in the screenshot below we can see that:
- Visitor connections have a 91-millisecond round-trip time, impacting how quickly the server and the browser can communicate
- 5% of navigations are back/forward navigations, but none of these are currently served from the back/forward cache
Monitoring Time to First Byte
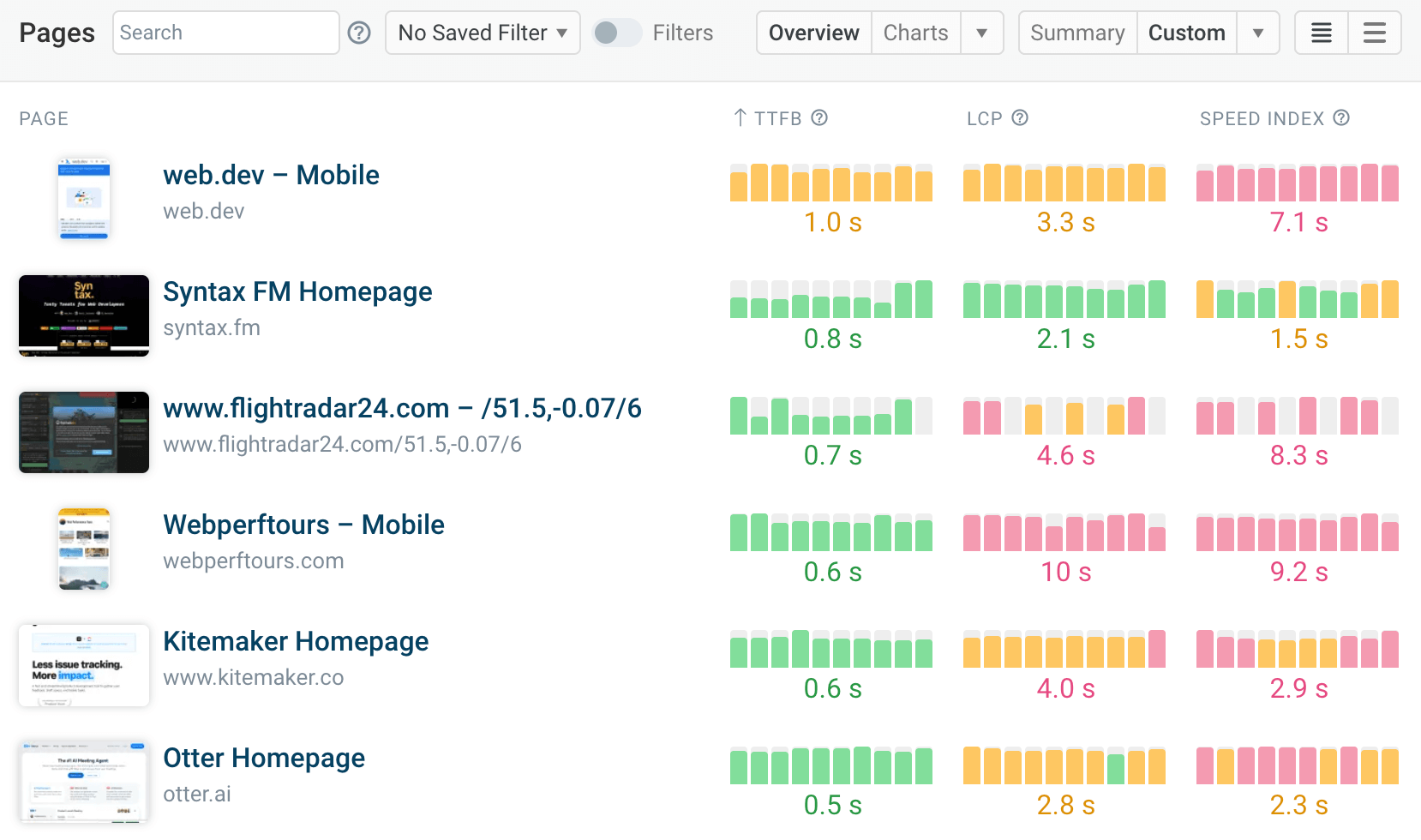
You can use DebugBear to keep track of TTFB and other Web Vitals metrics. Identify slow pages on your website, find out how to speed them up, and check if your optimizations are having the impact you hoped for.
DebugBear can also alert you to regressions by sending notifications over email, in Slack, or in Microsoft Teams.
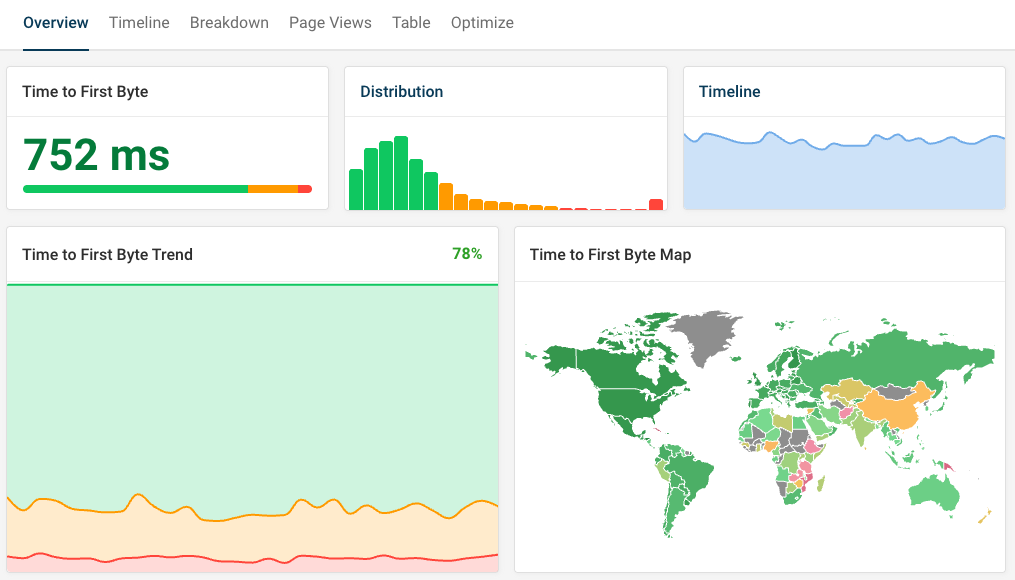
DebugBear not only runs regular synthetic website performance tests, but also provides in-depth real user monitoring to surface how different visitors experience your website.
In addition to TTFB you can also track user-focused metrics like the Largest Contentful Paint. DebugBear also keeps track of the two other Core Web Vitals metrics that impact Google rankings, Interaction to Next Paint and Cumulative Layout Shift.
Sign up for a free trial to start optimizing your website performance.

Monitor Page Speed & Core Web Vitals
DebugBear monitoring includes:
- In-depth Page Speed Reports
- Automated Recommendations
- Real User Analytics Data